今日はやよいちゃんの誕生日です。誕生日にこの記事を公開出来るのは嬉しいですね。
AFD紹介や雑記で書いたyayoiがやっと出来ました。ほんと大変でした。
とりあえずプロジェクト本格的に始めた19日から完成した23日までの話をします。
23日に完成したのに記事の公開を誕生日に合わせるという悪い人です。
ちなみにこの記事は作ってみたっていうだけであんまりTensorFlowの話とかはしません。
こんな感じに作れるんだなぐらいで読んでください。
そもそも、yayoiってなんだ?
話を始める前にこれ必要ですよね。
タイトルの通り、アイマスキャラの判定を行うプログラムです。
アイマスキャラと言っても今回は765PROのAS組13人に絞りました。
理由はいろいろありますけど、人数が少なくてデータセットが手に入れやすいっていうのが一番の理由です。ミリマスはアニメが無いからデータセットが若干少ないし(実はそんなに要らないことが後で分かりました)、デレマスはキャラが多すぎて自分が把握できてないという感じです。13人なら結構楽ですし、アニメもありますし、何より僕が全員判定出来ますw
ということでやることが決まったのでプロジェクト開始です。ここから日記のように日付ごとに書いていきます。
雑記を書いた頃
3月19日より前は実家に居たため、あまり進めていません。ですが、一応動かすためにいろいろ調べてました。
今回は以下の2つの記事を主に参考にさせてもらいました。
【秒速で無料GPUを使う】深層学習実践Tips on Colaboratory - Qiita
上が学習に関する記事、下が今回学習に使用したGoogle Colaboratoryに関する記事です。
Google Colaboratory(以降Colab)に関しては使い始めたときに説明します。
上のザッカーバーグ判定器のスクリプトをちょこちょこPython 3向けに書き換えるなどの作業はしていましたが、特に学習などはさせてませんでした。
ちなみにAFD紹介記事で見せたyayoiはザッカーバーグ判定器のWebUIを書き換える作業をしていたときのスクショです。
正直、今回のスクリプトはザッカーバーグ判定器を改造しただけです。ちょっとしたツール系のスクリプトは自分で書きましたが、根幹部分はほぼそのまま使わせてもらってますw
3月19日
さて、この日に香川の家に戻ってきました。ここから実際に制作に入ります。
まず、学習をさせるにはデータセットが必要です。そのデータセットを作っていきます。
今回、データセットにはアニメ、グリマスのカード画像、モバマスのカード画像を使用しました。各顔の画像サイズは64x64としました。
カード画像からのデータセット作成は非常に簡単です。前にやったアイコン作成スクリプトを少し改造すればすぐに取り出すことが出来ます。
取り出した結果はこんな感じです。
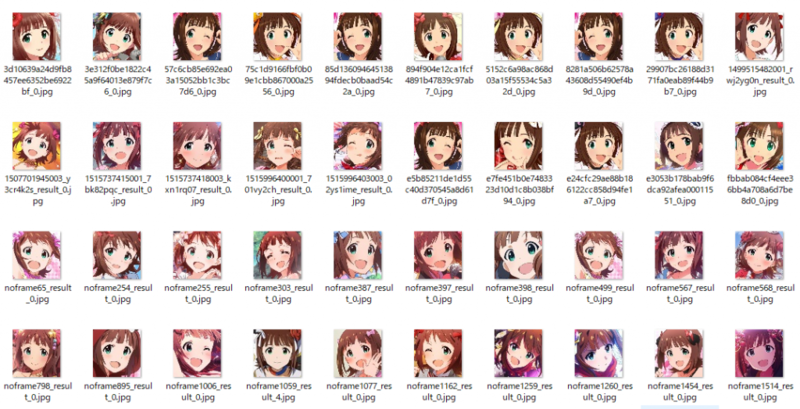
十分使えそうな感じになってます。
次にアニメです。ここからが大変な作業です。
まず、アニメ24話分から顔を取り出すスクリプトを実行させます。i5-6600Kの4スレッド全部を使って3時間半かかりました。長すぎ...
あと、ついでに使うかなーと思って負データ(AS組以外の間違い画像)を作成するためにA-1 Picturesが担当したアニメを適当に12話分ぐらい引っこ抜いて、こちらも顔を取り出しておきました。これも1時間ちょいかかりました。

で、これだけで疲れてこの日は終了です。
3月20日
さて、アニメ24話分取り出しましたが完全に顔がランダムになっています。

負データはバラバラでも1つのタグとして扱うのでいいのですが、キャラ判定をする上でこのままでは使えません。ということでタグ付け作業をやっていきます。
タグ付け作業は各タグ毎にフォルダーに分類する作業(これは無くてもなんとかなる)と画像パスとタグ番号を関連付けたデータベースみたいなファイルを作成する作業の2つがあります。
手動でフォルダーに入れていると腕が大変なことになる(画像は16000枚ぐらいあります)ので、専用のツールを作りました。というか昔作ってました。
元々TPTSで使用していたものですが、汎用性があるため使用しました。
これを使うとブラウザ上のUIでタグ付けを簡単にすることが出来ます。また、タグ付けした結果は逐一jsonファイルに保存されます。
UI自体はこんな感じです。(for TPTSになってることからもTPTSで使用していたって分かります。)

こんな感じで画像が出てくるので、それに対応したボタンをクリックしていきます。
これでも画像が16000枚ぐらいありますから超大変です。
で、半分ぐらい仕分けたところであることに気づきました。
「なんか同じような画像多くね?」
一応動画から切り出す際に1fpsになるようにフレームスキップを行っていたのですが、不十分だったようで同じ画像が大量に生まれていました。
ということで一旦ストップして画像を重複判定にかけることにしました。
重複判定は前説明したTPTSの重複判定アルゴリズムを使用しました。これで画像がなんと8000枚ぐらいまでに減りました。大体半分です。
ちなみに負データの方も重複判定をした結果、同じように半分ぐらいに減りました。
さて、画像は減ったのですがまた1から行うのはしんどいです。ということで元々出来ていたjsonファイルから消えた画像を取り除き、続きから出来るようにしました。ココらへんはスクリプトをサクッと書きました。
で、これをやって1日が終わりました。それもこの1日で完了してません。次の日に持ち越しです。マジでしんどかったぞ。
3月21日
さて、前日に引き続いてタグ付けを行い、作業を完了させました。
その結果、分類がこうなりました。

うーん、春香が異常に多いし、律子さんは少なすぎるというなんとも中途半端な感じになってしまってます。
ちなみにその他にはPだったり、小鳥さんだったり、モブキャラだったりが入ってます。これも後に負データとして扱います。
で、このデータにカード画像と負データを足し合わせます。その結果がこれです。

なんとも言えない。ですが、しょうがないのでこのまま行くことにしました。
さて、分類出来たのですが、現状はjsonファイル上でしか分類出来ていないのでフォルダー分けをしていきます。これも適当にPythonで行いました。
また、この作業を行う中で実際に学習に使うファイルと学習後のテストに使用するファイルとに分類します。これは学習データに特化した分類器が出来てしまうのを防ぐために行います。
これでデータセットが半分完成しました。ですが、枚数が少ないのが気になってしまいます。
なので、水増しをします。水増しをするのに下のサイトを参考にしました。
http://blog.aidemy.net/entry/2017/12/17/214715
水増し部分は左右反転、閾値処理、ぼかしを行っているようです。これで8倍にします。
ですが、全員を8倍にすると大変なことになるので枚数に合わせて処理を変更するようにしました。
で、ここまでの処理で出来た枚数をExcelに書き出してみました。

1/5化は後で使います。学習用水増し後を見てもらうと全部で46000枚以上になってます。
ちょっと多すぎましたかね?(実際、多すぎました)
これでデータセットが完成しました。ここでデータセットのファイル配置を書いてみます。

filesというフォルダーの中にstudyとtestというフォルダーがあります。studyは学習に実際に使用するデータが入っており、この中には0~13というタグ番号で画像を分類したフォルダーが入っています。testには学習後のテストに使用する画像が入っており、こちらも0~13のタグ番号で分類してあります。また、study.jsonとtest.jsonにはそれぞれのフォルダーに入ってる画像とタグ番号が対となった形式でリストが作成されています。

さて、このデータセットを用いて実際に学習をさせていきます。
まず、データセットをそのまま使用して、ザッカーバーグ判定器のスクリプトを64x64に対応させただけで実行させてみました。
まあ、上手く行くとは思ってないのでエラーを吐くことは分かっています。
そもそもスクリプトが走りませんでした。エラーで調べてみると古い関数を使っていたようです。
ということで上の記事を参考にして修正し、走らせます。

どうもテンソルの形状が一致していないようなので、数値を書き換えます。さてさて、どうなるかな?
また同じようなエラーが出ました。しかも、先ほどよりも100倍ぐらい大きい数値が出てます。
しょうがないので、その値にすると次はメモリーが足りねーぞって怒られてしまいました。困りました。
まあ、この時点でバカ丸出しです。畳み込み層とプーリング層で画像を変化させて行くのですが、そこの計算を僕は全く行わず当てずっぽうで行っています。こんなことで上手くいくはずがありません。
で、いろいろ調べて以下の記事にたどり着きました。
ここのニューラルネットワークの形状を見て、やっと理解しました。
ということできちんとした値に変更してやると上手く動いてくれました。
ここで古い関数に関するWarningが出ていたので、そこも修正しました。
さて、ローカルで走ることが判明したのでColabに投げます。
ここでColabの説明です。ColabとはGoogleさんが提供してるPythonの実行環境です。
それもただの実行環境ではありません。なんと無料でTesla K80が使用できます。
まあ、流石にフルでは無いでしょうけど...
それでも凄すぎます。特にGPUが無い僕みたいな人にはとってもおすすめです。
ですが、無料ですので連続で12時間しか使用できません。12時間経つと仮想環境を消されます。そのため、データセットとかもその都度置く必要があります。
まあ、詳しい説明は上で紹介したQiitaの記事が一番ベストです。
こんな感じの神のような環境を今回は使用しました。12時間しか使えませんが、実際の学習は1時間ぐらいなので全く問題ありません。
で、この環境を使う上で一番面倒なのがデータセット等のファイルの受け渡しです。
一番ベストなのがQiitaの記事でも紹介されているようにGoogle ドライブを使用することです。僕もこれで行いました。
特にうちの大学はG Suiteが使えるので、Google ドライブが容量無制限で提供されています。これがあれば怖いものなしです。素晴らしい連携だ。
走らせてみます。エラーを吐きました。どうもflagsがなぜか二重定義されているようです。
意味が分からなかったので、flagsの部分をただの変数にしました。別にこれでも問題はありません。
これで走らせたのですが、流石に46000枚は多すぎたようです。メモリーが足りないというエラーが出ました。
そのためにデータセットを1/5にしました。Excelの1/5化はここのことです。
さて、走る分量になったので学習させてみます。

はて?なんだかおかしなことになってますね。もう1度実行してみましょう。

これもおかしいです。困りました。
さて、対策を探します。見つけました。
log(0)になってしまうのが問題だったようです。ちなみにザッカーバーグ判定器で学習を走らせるところでも同じようなことがおり、コメントに対策が載っていました。
ということで今回は毎回1e-7を足すようにしました。これで0にはなりません。
さて、学習をしている間に日付が変わってしまいました。
3月22日
日付が変わってしまいましたが、これで学習が出来ました。
僕が今振り返っていて一番やらかしたと思ったのは、ステップ数とバッチサイズを記録してないんですよね。というか動かないと思って、ほとんどの学習データを消したんですよ。多分動くのに...
学習データをyayoi本体に入れてWebUIを実行してみます。

リサイズしたら文字が潰れてしまいました。ですが、大体分かると思います。
全くうまく動いてねーよ!!!!!
どうして、どうしてなの。やよいちゃん、何があったんだ。
それも判定が超遅い上にメモリーを大量に消費します。この時点ではGPUが無いからしょうがないかぐらいで考えてました。
ちなみに途中で暴走してメモリー使用量がこんなことになったこともあります。

11GBって食い過ぎでしょ。やよいちゃん、お姫ちんみたいな胃でも持ってるのか...
この時点で考えていたのが、「学習回数が足りない」「ニューラルネットワークのモデルが悪い」「データセットが悪い」の3つでした。
ですが、このどれでもありません。いや、データセットが悪いも一応当てはまるか...
本当の理由は23日に判明します。
ということでまず簡単な学習回数が足りないという問題を解消する方法に出ました。
やり方としては、100ステップごとにテストデータによる判定を実行してその精度が一定値以上になったら終了するという方法をしました。これで永遠と学習を進めてくれます。
ということで、この学習をして一旦昼ぐらいまで寝ます。
さて、起きました。学習データが出来ているので、使ってみます。
ダメでした。ほとんど同じ状態になっています。
さて、次にニューラルネットワークの形状をいろいろ変えてみます。具体的には畳み込み層とプーリング層を2~4つの間で変化させたり、フィルターサイズを3x3~10x10の間で変化させたりしました。
ここでTensorBoardの学習記録を見てみます。これは確か畳み込み層とプーリング層を3つにして、フィルターサイズを3x3にしたときのものです。

なんだか面白いグラフになってますね。どう考えてもおかしいです。
ちなみにColabでTensorBoardを使うには少し工夫が必要です。
で、次に目を付けたのがデータセットです。そもそも枚数がこんなに必要だとは思えません。
ということで精査してみます。実は水増しした後にきちんと見ていませんでした。
すると酷い画像がいろいろ出てきました。

これは閾値調整で失敗して黒く潰れてしまっています。

こっちは顔以外の負データです。まあ、特に問題は無いのですが一応省きました。
で、ここで気づいたことがあります。
「負データ、入れないほうがいいのでは?」
負データはデータセットを作成したときにも言いましたが、A-1 Picturesの適当なアニメをごちゃまぜにしています。つまり、一貫性が全くありません。
ということは特徴量も出にくくなると考えました。ということで負データを省いた学習に切り替えました。
その結果、データセットが以下のようになりました。

全体の枚数が減っているのは使えないかなと思った画像を消した結果です。また、各キャラごとに枚数がばらつかないように200枚ぐらいになるようなjsonファイルも作成しました。
これでデータセットもほぼ完璧です。学習させてみます。
ダメでした。どうしてなのでしょうか。

学習を何回も行わせているとこんな感じにグラフになっています。特に問題なく学習出来ているようです。

100ステップごとのテストも97%ぐらいの値を叩き出しています。
どう考えてもおかしいです。この辺りで相当イライラしています。
最終的にGPUで学習させてCPUで推論しているのがダメなのでは?とかいう頭のおかしな結論を出して、ローカルで学習させることにしました。ちょうどColabも12時間近く動かしていましたからいいタイミングだと考えました。
ということで学習をさせて寝ました。400ステップぐらいなのですが、やはりCPUは遅いです。
3月23日
ローカルで作成したモデルを入れてみました。ダメです。全く判定されません。
さて、ここまで来てやっとWebUI側の推論部分に目を向けました。
というか学習時のテストで97%も叩き出しているのに、上手くいかないほうがおかしいのです。
で、きちんとスクリプトを読んだりググったりした結果、バグを見つけました。
ザッカーバーグ判定器では最初の顔だけ、つまり1つだけしか判定しないようになっています。
ですが、yayoiでは出てきた顔全てを判定するようにしています。
このとき、顔ごとにモデルを読み込んでいるのですが毎回tf.reset_default_graph()を呼び出さないといけないのに最初の1回目しか呼び出していませんでした。
また、tf.Session()の書き方も変えました。これでやってみます。

やったぞーーーーーーーーー!!!
動きました。春香がきちんと判定されていませんが、これは90%を切っているからです。判定詳細ではきちんと判定されています。(青枠がAS組、赤枠がそれ以外になっています)
すごいです。やよいちゃんは出来る子だったのです。
ということで、一番悪かったのはWebUI側の推論でした。また、この修正で判定が即行われるレベルに早くなりました。メモリー使用量も問題ありません。
試しにColab側で1000ステップぐらい行ったものを使ってみました。

すごい、凄すぎる。やっぱり自分は完璧さー!
ということで完成しました。非常に長い道のりでした。というか相当回り道をしました。
さて、ここで試しにAS組が全く写っていない画像を投げてみます。

うーん、ダメですね。なんか髪の色で判定してないかい?
ということでもう少し頑張って学習させたほうが良さげです。負データ入れてやり直してもいいかもしれません。
これがyayoiが完成するまでの話でした。
データセットが必要なので、誰でも学習させられるって感じではありませんが参考になれば幸いです。
なんとかやよいちゃんの誕生日までに完成してよかったです。本当によかった...
さて、これをサークル発表向けのLTにまとめようと思います。では!